【方法论】因果推断实战:如何用DID+DML+SCM发顶刊?(含文献领取)
特别说明
本文整理了三种主流因果推断方法的实战要点,结合真实论文案例。为了方便大家学习,本文涉及的所有文献(含PDF)均可免费领取!
一、双重差分法(DID):政策评估的黄金标准
适用场景: 评估某项政策/事件对处理组vs对照组的影响
经典文献:
| 文献 | DOI | 期刊 |
|---|---|---|
| Acemoglu, Naidu, Restrepo, & Robinson (2019) - Democracy Does Cause Growth | 10.1086/700936 | Journal of Political Economy |
基本原理:
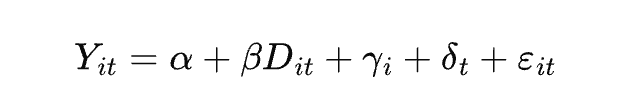
其中 $D_{it}$ 是处理变量,$\gamma_i$ 和 $\delta_t$ 分别是个体和时间固定效应。
核心假设: 平行趋势假设——政策实施前,处理组和对照组的变化趋势应保持平行
实战要点
| 步骤 | 关键操作 | 常见问题 |
|---|---|---|
| 1. 构造控制组 | 选择与处理组特征相似的对照组 | 对照组选择不当导致结果不可信 |
| 2. 平行趋势检验 | 事件研究法(Event Study)画图 | 政策前趋势不平行,考虑使用合成控制法 |
| 3. 安慰剂检验 | 随机分配政策时间/对象 | 结果不稳健可能被质疑 |
| 4. 异质性分析 | 按地区、行业、企业规模分组 | 揭示政策效果的差异化影响 |
Stata实战代码
* 双向固定效应 DID 回归
reghdfe y treat post, absorb(i.id i.year) vce(robust)
* 平行趋势检验
gen period = year - policy_year
forvalues i = -5(1)5 {
gen treat_`i' = (treat == 1 & period == `i')
}
reghdfe y treat_*, absorb(i.id i.year) vce(robust)
* 画图展示
coefplot, vertical keep(treat_*) yline(0)二、双机器学习(DML):解决内生性的新武器
适用场景: 处理内生性问题(遗漏变量偏误、测量误差、双向因果)
核心文献:
| 文献 | DOI | 期刊 |
|---|---|---|
| 吕镯等 (2025) 人工智能对企业成长的影响研究 | 10.19571/j.cnki.1000-2995.2025.05.006 | 科研管理 |
基本原理
两步残差回归:
- 用ML模型预测 $Y$(控制变量 $X$)和 $D$(控制变量 $X$)
- 对残差 $\tilde{Y}$ 和 $\tilde{D}$ 做简单回归,得到因果效应估计
核心优势: 可以使用高维协变量,自动进行变量选择,有效缓解遗漏变量偏误
Python实战代码(基于DoubleML库)
from doubleml import DoubleMLData, DoubleMLPLR
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
import numpy as np
# 构造数据对象
data = pd.DataFrame({
'Y': outcome, # 结果变量
'D': treatment, # 处理变量
'X1': controls[:, 0], # 控制变量1
'X2': controls[:, 1] # 控制变量2
})
dml_data = DoubleMLData(data, y_col='Y', d_cols='D')
# 使用随机森林作为基学习器
ml_l = RandomForestRegressor(n_estimators=100, max_depth=5)
ml_m = RandomForestRegressor(n_estimators=100, max_depth=5)
dml_plr = DoubleMLPLR(dml_data, ml_l=ml_l, ml_m=ml_m)
dml_plr.fit()
print(dml_plr.summary)
三、合成控制法(SCM):当DID失效时的替代方案
适用场景: 政策只影响少数单位(如一个国家、一个州),无法找到合适对照组
核心文献
| 文献 | DOI | 期刊 |
|---|---|---|
| Abadie, Diamond, & Hainmueller (2010) Synthetic Control Methods for Comparative Case Studies | 10.1198/jasa.2009.ap08746 | Journal of the American Statistical Association |
| Acemoglu, Naidu, Restrepo, & Robinson (2019) Democracy Does Cause Growth | 10.1086/700936 | Journal of Political Economy |
基本原理
通过加权组合多个未受政策影响的单位,构建一个"合成对照组":
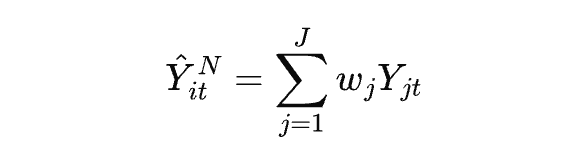
其中 $w_j$ 是权重,通过最小化政策前时期处理单元与合成控制单元的差异得到。
Python实战代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 简化的合成控制法实现示例
# 假设 data 是面板数据,包含处理组和对照组
# 处理组
treatment_unit = 'CA'
pre_period = range(2000, 2008) # 政策前时期
post_period = range(2008, 2015) # 政策后时期
# 计算合成控制权重(简化版,实际使用优化算法)
# 这里仅展示思路,完整实现建议使用 Synth 包或手动优化
control_units = ['TX', 'NY', 'FL', 'IL', 'PA']
# 构造合成控制
synth_outcome = np.zeros(len(pre_period) + len(post_period))
for i, year in enumerate(list(pre_period) + list(post_period)):
# 简化:等权重平均(实际应使用优化算法求解最优权重)
weights = np.ones(len(control_units)) / len(control_units)
synth_outcome[i] = sum(
weights[j] * df[df['unit'] == control_units[j]][str(year)].values[0]
for j in range(len(control_units))
)
# 可视化
plt.figure(figsize=(10, 6))
plt.plot(years, treatment_outcome, label='实际 California', linewidth=2)
plt.plot(years, synth_outcome, label='合成 California', linewidth=2)
plt.axvline(x=2008, color='red', linestyle='--', label='Prop 99 实施')
plt.xlabel('Year')
plt.ylabel('Cigarette Sales per Capita')
plt.legend()
plt.title('合成控制法:加州控烟法案效果评估')
plt.show()四、方法选择指南
| 方法 | 适用条件 | 数据要求 | 难度 |
|---|---|---|---|
| DID | 多处理单位、存在对照组 | 需要面板数据 | ★★☆ |
| DML | 高维协变量、内生性严重 | 大样本 | ★★★ |
| SCM | 政策只影响少数单位 | 需要多个未受影响的对照单元 | ★★☆ |
五、实战建议
1. 优先考虑DID
- 方法成熟,审稿人接受度高
- 关键是平行趋势检验要扎实
2. 尝试DID+安慰剂组合
- 增强结果稳健性
- 顶刊标配的检验序列
3. DML适合创新性要求高的研究
- 方法创新本身就是边际贡献
- 但需要较大的样本量支持
4. SCM适合政策评估类研究
- 适合只有一个处理单元的情况
- 图形展示直观,论文呈现效果好
参考文献领取
| 序号 | 文献 | DOI |
|---|---|---|
| 1 | Abadie, Diamond, & Hainmueller (2010) | 10.1198/jasa.2009.ap08746 |
| 2 | Acemoglu, Naidu, Restrepo, & Robinson (2019) | 10.1086/700936 |
| 3 | 吕镯等 (2025) | 10.19571/j.cnki.1000-2995.2025.05.006 |
你在实证研究中用过哪种因果推断方法?遇到过什么问题?
评论区聊聊,优质留言有机会获得额外PP币奖励!
本文信息来源:各大期刊官方及公开数据库

