【stata实证】熵值法的代码实现
在对指标进行赋权的时候用到了熵值法,整理了一下熵值法的stata代码和示例数据,分享给大家。
熵值法是一种依据各指标值所包含的信息量的多少确定指标权重的客观赋权法,某个指标的熵越小,说明该指标值的变异程度越大,提供的信息量也就越多,在综合评价中起的作用越大,则该指标的权重也应越大。熵值法可单独进行综合评价;也可以与其他方法相结合,如层次分析法,用熵值法确定各指标的权重,然后运用层次分析法得到各个评价对象的综合得分。
熵值法的具体过程主要有以下几个步骤:
第一步,指标标准化。
对于正向指标: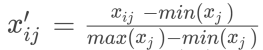
对于逆向指标: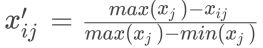
第二步,计算第i个研究对象下第j项指标的比重pij。

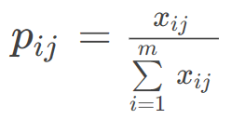
第三步,计算第j项指标的熵值ej。

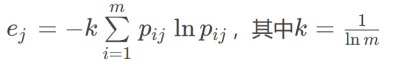
第四步,计算第j项指标的差异系数gj,差异系数越大越好,表示该指标对于研究对象所起的作用越大,该指标较好。

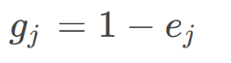
第五步,给指标赋权,定义权重wj。

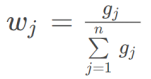
第六步,通过权重计算样本评价值,第i个研究对象下第j项指标的评价值为:

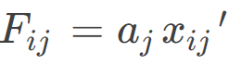
则第i个研究对象的总体评价值为:

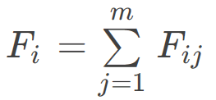
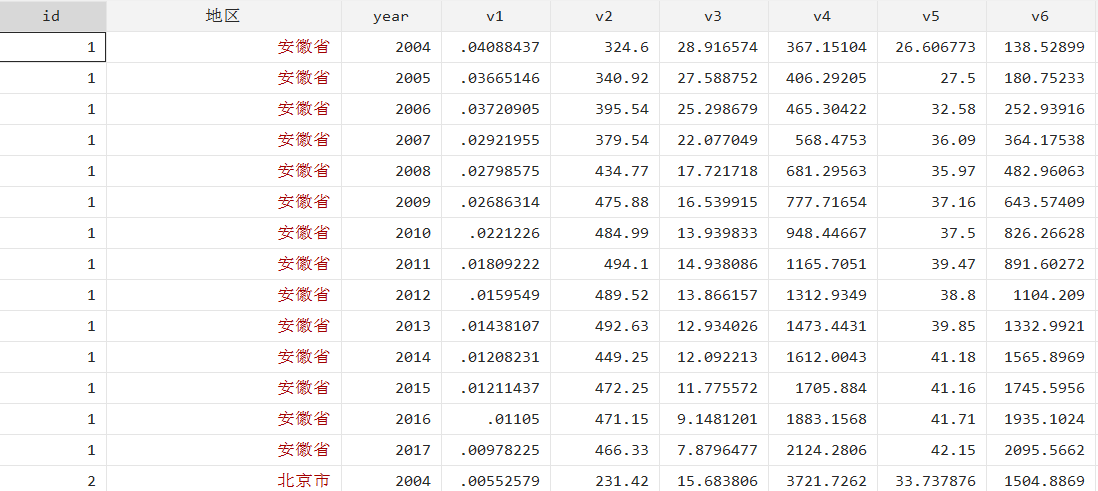
部分数据展示: